
Post N: How an LLM is trained
Bonus Weekend Post!

Edit 1: I promised an update a couple weeks ago that incorporated information about audio an visual information, or multimodal training. This update includes that.
Caveat 1: I am not a computer scientist. I did my best here but am going to consider this a living document. I will come back and update it with corrections and when I come to understand the process better, or when I think of better ways to explain things. I am hoping though, that because I am not an expert, I will be able to explain this in a way that is understandable to other people who are also not experts, that the terms and concepts that threw me will be the same for you, and the extra explanations that helped me to at least think I understand them, will help you as well.
Caveat 2: This stuff is really dense. It took me a month of intense conversations with ChatGPT to get this far. I am hoping it is readable and understandable, but I am now so deep in it I pretty much have no idea. Comments about how understandable this is are welcome! (Provided you can actually get through it!)
__________________________________________________________________________
Alright, I’m going to give this a shot. I’m going to try to explain what I’ve learned about how LLMs like ChatGPT are trained in a way that’s clear, concise, and not so boring that it becomes unreadable.
Let’s jump right in:
The developers of LLMs start with massive text, video, and audio data sets. These data sets are, (in theory), all public domain or licensed materials, from the works of Shakespeare to computer coding repositories, from news articles to Wikipedia, from scientific journals to the Bible.
I, (and ChatGPT) did some poking around the web and although the figures aren’t publicly available from OpenAI, we got a consensus estimate that the model I use most, ChatGPT 4, was trained on 1 petabyte of data. For context, as that number is probably as meaningless to you as it was to me, that equals approximately the same amount of text data as 322,580,645 copies of War and Peace, or approximately 250 million copies of the Bible.
The data goes through a pipeline of programs and steps to clean it. This includes removing duplicates, formatting it for processing, and curating it to remove factual inaccuracies.
For text data: Once this step is complete the data is broken down into tokens or words or word parts, like “cat” or the “un” and “happiness” in unhappiness. These tokens also include punctuation marks and emojis and digits and special symbols used in programming and more. Essentially all the pieces that will be needed to comprehend all sorts of questions from LLM users and to be able to effectively respond to them.
Visual and audio files are also tokenized, converted into vectors, and integrated into the token matrix just like text tokens. These vectors undergo the same relational training process as text-based vectors.
In total, all of these tokens make up the LLMs “vocabulary.” ChatGPT and I found a wide range of estimates for total numbers of unique tokens after cleaning:
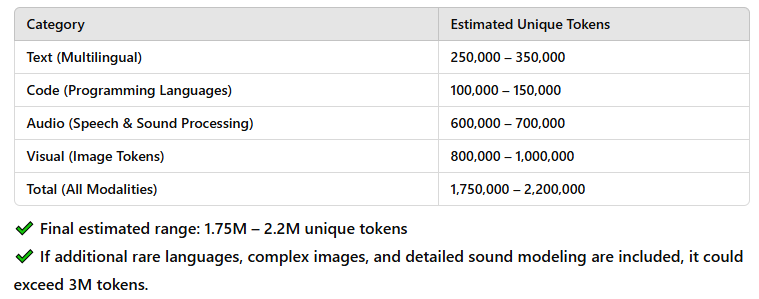
Alright, here’s where things start to get interesting—or at least they do to me. This is also the part where it gets really, really confusing. I’m going to do my best to make it as understandable as possible and distill a couple of weeks of intense (and sometimes humbling) conversations with ChatGPT into a few digestible paragraphs.
Let me break this down as simply as I can. For those of us on the humanities side, it’s worth noting: computers and software don’t “think” in words like we do. Their language is numerical, not verbal. So, for an LLM to do its thing, it has to essentially translate all the tokens into numbers. It starts by assigning a unique numerical ID to each token, and then—through a process called embedding—it assigns a vector to each ID. (Okay, okay, I probably just lost some of you, my humanities people. I will explain vectors in a moment, and I swear that this is going somewhere and will eventually tie into the consciousness discussion way down the road in later posts. That is the reward for all of this for you weirdos like me who care about such things).
Okay, what the hell is a vector. . .The Oxford Dictionary defines. . .lol, just kidding! In this context, a vector is just a (really) long list of numbers. That’s it. And this is important because? . . . why? you ask? Each individual number in this very long list of numbers, (I am getting estimates of 12,000 to 16,000 for Chat-GPT 4, for the purposes of this exercise, let’s just say 16,000), represents what I like to think of as an “aspect of meaning” for the token. And every token has one associated vector with that same number of numbers in it, (16,000 in this example).
ChatGPT likes to give this example: Take the token “cat.” The first number in the vector for cat could indicate something like “pet-ness.” So, that first number in its vector is likely to be relatively high because there are strong correlations between cats and pets, right? Whereas if you take the token 'car,' that first number, which indicates pet-ness, is likely to be lower than that for 'cat,' as there aren’t as many correlations. (This part at least, is pretty intuitive I think).
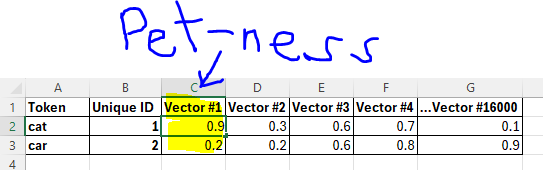
Important point here, when thinking of the two tokens, “cat” and “car”, you need to understand that there are the same number of numbers in each vector, and the “aspects of meaning” line up with each other in columns, (as shown above). If this weren’t so, there would be no way to compare “pet-ness” between the cat and car. . . Make sense?
And there are as many aspects of meaning as there are columns. So, if column one is 'pet-ness,' then column two could be 'redness,' column three 'Britishness,' and column four ‘that-very-specific-annoyance-when-a-recipe-is-buried-under-a-long-blog-post-about-someone’s-trip-to-Tuscany-ness,' and so on, (numbers in vectors 2-4 above likely not depicted accurately).
For a visual example, instead of predicting “What sat on the mat?” → “Cat,” the model might predict that an image contains a cat (or associate the text token cat with the visual token representing the cat). We can also assume that the vector for the image of a cat has a high ‘pet-ness’ aspect of meaning (or semantic property), just as the word cat would in text-based representations.
And then this goes through the same training process several billion times until I can upload a picture of my cat, General Snacks, and it can tell me accurately that I uploaded a picture of a “fluffy orange cat laying on its back in the sun yawning.”
You might be noticing a problem here: 16,000 aspects of meaning are a lot, but nowhere near enough to capture all the nuances of language. So, in practice, once the model is trained, each column likely ends up representing a blend of multiple aspects of meaning. Or, alternatively, a single concept like 'pet-ness' might be blended across several or many columns. This is actually an area of ongoing research—figuring out what these columns really represent in a trained model. But for now, let’s keep it simple and imagine each column corresponds to just one concept, like 'pet-ness.'
Alright! so recall, the vocabulary for the LLM is roughly 100,000 tokens, that means that table we started above with the cat and car tokens and their 16,000 corresponding numbers, (the vectors), also has roughly 99,998 more rows beneath for all the other tokens and their respective numbers, (vectors). And for each of these 100,000 tokens, that first column is going to give a numerical score for “pet-ness,” just like it does for cat and car. (Again, take the token “dog”, high pet score, and the token “taco,” lower than “dog” but probably higher than “Mitsubishi,” (because at least there is a possibility that something you may eat in a taco could be construed as a pet. . . although, a Mitsubishi in some contexts might run over a pet. . . so the value for Mitsubishi might not be as low as you think. . .maybe you can see why I called these “aspects of meaning”. . . the way I have come to understand it, there is a lot of possible context to these numbers and later, it will hopefully make sense to you as to where all this context comes from).
Okay...where were we? Is all that making sense so far? As I mentioned, those 16,000 columns each represent an 'aspect of meaning' or nuance for the tokens. So, the more numbers in the vector, the more subtlety or richness the LLM can potentially capture in its communication. I call these 'aspects of meaning' because it helps me wrap my head around what’s happening, but technically, this is referred to as the model having 16,000 dimensions. The more dimensions it has, the richer and more complex its understanding could theoretically become. That said, there are trade-offs: adding more dimensions requires more computational power, and at a certain point, the returns start to diminish. (How much richness and complexity we can squeeze out at this time is another question entirely, but let’s not get sidetracked by that right now).
Now I’m going to throw you for a loop (or at least, this one threw me). Despite what I just told you about the first column being “pet-ness”—or, more accurately, something far richer than just “pet-ness”—that only applies to a trained model. During training itself, these columns don’t represent any fixed “aspect of meaning.” In fact, as we’ll see, the meaning represented by each column shifts and changes throughout training. (Once the model is trained and being used, like how you and I use it, the circumstances change again and the aspect of meaning for each column becomes “fixed” if still hard to pin down. Hopefully, this will make more sense as I describe how the actual training works.)
Okay, just a note, that entire process I just described, the assigning of vectors to each token’s unique ID, is called embedding. This is the last step before the training actually begins.
In the beginning. . .
Let’s take a step back for a moment. Picture that table again—the one with around 16,000 columns and 100,000 rows. A spreadsheet! (Well, technically, it’s a matrix, but for our purposes, let’s stick with 'spreadsheet.') In this spreadsheet, the far-left column lists the unique ID numbers for every token. These tokens include 'cat,' 'car,' 'run,' 'Kardashian,' 'pink,' 'the,' '@,' '-ism,' and so on—all the words, word parts, language elements, coding symbols, and anything else that might show up as an output when you’re chatting with the fully trained LLM later. Essentially, it’s everything the model could ever need to process and respond effectively.
And the top row of the spreadsheet? Well, the only thing there is the vector number. Remember, (I said it and I am saying it again), even though every column represents an aspect of meaning, we can’t determine a fixed meaning during training because those meanings aren’t defined yet and will change and morph during the process.
So, what’s in all the cells to the right of those unique IDs before we start training?
“Duh!” Says Mr. Strawman, “the vector numbers for all of the tokens! You know Mr. Writer, those numbers that you told us represent how much “pet-ness” the token “cat” has!”
“But. . .” says Mr. Writer smugly, “how could there be any numbers in those cells that represent anything? The model is a clean slate. . . it hasn’t been trained at all yet, there is no way it can have any meaning assigned.”
Mr. Strawman replies, “I dunno, are they empty?”
“No!” Says Mr. Writer triumphantly (and obnoxiously), “there are numbers in the cells, but to start with they are all assigned completely randomly!”
“Huh, how does that work?” Replies Mr. Strawman.
“I will explain,” says Mr. Writer.
Okay, so that is enough of that nonsense. Initially, all the numbers in the matrix are indeed assigned randomly. This is fine because the model will update all of the numbers through repeated stages of training.
So, how is the LLM actually trained? I’m not going to lie—this part is complicated. For someone like me (a humanities person whose memory isn’t exactly what it used to be), it took a few weeks of asking ChatGPT the same questions over and over to even start wrapping my head around it. But I’ll do my best to break it down for you. Here it goes:
This matrix (spreadsheet) is fed into the transformer (the 'T' in ChatGPT), the program that enables the model to process and understand relationships between tokens. The transformer then takes each and every vector and splits it into three new vectors, called the query, key, and value vectors. So now, if you’re keeping track, the spreadsheet has 300,000 rows. Not that this really matters, but for people who are visual learners like me, imagining the table tripling in length somehow helps me wrap my head around it. (If it doesn’t help you, then don’t imagine it.)
Okay, so here’s where the magic starts. I think I am first going to give a “simplified” version that captures the basics, (I say simplified, but it is relative, believe me), and then a more elaborate version that really gets into how the sausage is made. If you made it this far, I should maybe assume you want the full sausage, but I am going to give you the option to read the simplified version and skip over the meat grinding if you want.
The Simplified Version
The query vector for every single token 'calls out' to the key vectors for every single token, including itself, and asks, 'How relevant are you to me?' The key vectors then reply to each query vector, 'This is how relevant I am!' Once they’ve worked this out, depending on how relevant the tokens agree they are to each other, they interact with the value vector, where the relative aspects of meaning are stored during this process. Together, they decide how important each aspect of meaning is for every token. These updated values essentially become the new token vectors for each token as they move on to the next round of training (with a few intermediary steps omitted here in the simplified version).
Okay, so what the heck does that last paragraph actually mean? It's a bit of a clunky analogy, but it’s the one ChatGPT uses, and I couldn’t think of a better one—so I used it too. Let’s talk a little bit about what actually happens and then we can get back to why the analogy sort of works.
What really happens is that each number in every query vector is multiplied by each number in its own key vector and every other key vector. This is why ChatGPT calls this the query vector ‘calling out’ and the key vector basically ‘answering’. Because the query vectors for every token mathematically interact with the key vectors for its own token and every other token.
Essentially the model is checking how relevant every aspect of meaning in every token is to every other token. It is discovering how all of the tokens define each other. And this is done through brute computational force and the use of a ton of actual training data that was gathered that we spoke about earlier. This is where the model begins to understand meaning—not through predefined rules, but by observing massive amounts of training data and adjusting its internal numerical relationships accordingly.
Now, let’s talk about the training data itself, because this process isn’t happening in a vacuum. As mentioned before, the model is trained on massive amounts of tokenized text, broken into smaller, manageable chunks called batches. Each batch contains sequences of text taken from the training dataset. For example, one batch might include sentences like "The cat sat on the mat" and “wherefore art thou Romeo?", During training, the model processes one batch at a time, focusing on predicting the next token in each sequence. For instance, given the input "The cat sat on the. . ." or “wherefore art thou. . .?” the model’s goal is to predict "mat" and “Romeo.” This next-token prediction task is the foundation of how the model learns.
Then the model essentially checks its own work. It does this by running a sort of test prompt, similar to how you or I use ChatGPT. Let’s go back to the example of “cat.” Say the prompt is, “What sat on the mat?” The correct answer is supposed to be “cat.” But if the model predicts “pizza” instead, it knows its prediction was off, and its relational vectors need improvement.
To fix this, the model takes a step called backpropagation, where it tries to figure out where it went wrong and adjusts its weights. (Yes, there are other matrices involved here—one for each of the three vectors: query, key, and value. Just like our main table, these matrices start out random. But since this is simplified, I’m not diving too deeply into that right now.)
During backpropagation, the model goes back to these three matrices and updates them, tweaking the weights to get closer to the correct answer: “cat.” Once it makes these adjustments, the entire process runs again.
Basically, it just does this again and again and again, getting better each time until it nails “cat”. (And, essentially, every other question you can think of, based on the equivalent of 250 million Bibles' worth of text data it was trained on. My takeaway from this is that it does a very good job at avoiding, really better and better with each model upgrade. . . hallucinations. . . when it is just using this training data. It seems to me it gets in trouble more now when trying to integrate new data from the web. . . but that is really neither here nor there for the moment.)
This doesn’t happen a few times. It happens billions of times. The result? A model that has seen so much data and refined its parameters so extensively that it cannot only predict “cat” for “What sat on the mat?” but also provide nuanced and seemingly creative answers to almost any prompt you can think of.
So... before we get to the sausage, what are the takeaways here for me?
Well, first off—pretty cool, huh? It ends up being able to predict (or answer prompts) correctly really well. I mean, so well that for all intents and purposes I think it passes the original Turing Test by doing what? Comparing a bunch of numbers on a massive spreadsheet? (Yes yes, a few billion times, but still. . .) To me, that’s totally crazy.
Second—and even more interesting to me—these models learn by association. While they’re just associating numbers, the sheer scale of their training and the complexity of the relationships they form lead to emergent abilities—things that sure seem a lot like nuanced understanding, reasoning, and even creativity. At the very least it seems to me these models are thinking and exhibiting a form of intelligence in a way that I don’t think we can just dismiss because the language is numerical rather than verbal.
Third, humans also learn by association to a large extent (e.g., we associate "fire" with "hot" through experience). LLMs, on the other hand, as stated, learn by associating numbers derived from concepts. But what happens when sensory experiences start to come into play—when these models begin accessing video, sound files, and more? (Which is happening). What about actual sensory input through cameras, microphones, or even haptic devices? (Also happening). That’s a whole new dimension to think about, and it’s something I mean to explore in future posts now that this one is (finally) published.
________________________________________________________________
Okay, what follows is the (less) simplified version for those who are interested. This is optional, (as if the whole post wasn’t optional lol). It is basically just a rewrite of the above with more added in.
(Additionally, please note that for this section I did something I don’t normally do here on my Substack, I fed my writing directly into ChatGPT and asked that it look for opportunities to make the explanations clearer and check if I am leaving things out. I struggled in deciding whether to do this or not, but because this is supposed to be the “Full Sausage,” and I tend to jump all over the place in my writing, I made an exception, whereas normally I want to keep my voice and the LLMs voice completely separate. I’m not planning on doing this often and will confess when I do. It did suggest changes and let me know where I missed something, and I did incorporate some of its advice).
The Full Sausage:
Let’s start here again from earlier, “This matrix is fed into the transformer (the 'T' in ChatGPT), the program that enables the model to process and understand relationships between tokens. The transformer then takes each and every vector and splits it into three new vectors, called the query, key, and value vectors. So now, if you’re keeping track, the spreadsheet has 300,000 rows. Not that this really matters, but for people who are visual learners like me, imagining the table tripling in length somehow helps me wrap my head around it.”
Here’s where the magic of the transformer starts. Every token’s query vector essentially "calls out" to the key vectors of every other token, including itself, and asks, “How relevant are you to me?” The key vectors respond to the query with their dot product, which is calculated by multiplying each number in the query vector with the corresponding number in the key vector and summing these products into a single number. This gives a relevance score for every pair of tokens.
Now, to ensure these scores don’t get too large or too small (since the dot product can vary widely), the model applies a normalization step called scaling. It divides the dot product by the square root of the vector’s length (in this case, approximately √16,000). Apparently, this keeps the scores more stable and easier to work with.
These scaled scores are then passed through a softmax function, (sounds like a 90’s techno band, or a movie I would stay up late to watch at a friend’s house when I was 13 and we didn’t have premium channels at home. . . sorry, I’ll try to keep the asides to a minimum going forward), which converts them into attention scores—values between 0 and 1 that represent how much attention each token should give to the others. In other words, the attention scores determine how strongly a token is influenced by another token during this process.
Once the attention scores are calculated, they’re applied to the value vectors. Each value vector’s numbers are scaled by the attention score for their respective token pair. This step ensures that tokens considered more relevant (according to the query-key interaction) have a larger influence on the resulting output. These adjusted values are summed together, producing an updated vector for each token. This new vector now encodes the "importance-weighted" meaning of the token relative to all the other tokens.
This process is called self-attention (no comment. . . but only because I said I was keeping the asides to a minimum, but really, this one is low-hanging fruit), because the model is evaluating the relationships between tokens within the same input sequence.
After the self-attention step, the updated vectors go through additional layers in the transformer, like the feedforward layer. This layer processes each token vector individually, combining its features in new ways using learned weights and biases. This helps refine the token’s representation by incorporating more complex patterns and interactions. Importantly, after each step, the model applies normalization to stabilize learning and ensure that values don’t diverge too much.
Once the vectors are updated, the model essentially "checks its own work." It does this by running a test prompt, much like how you or I use ChatGPT. For example, say the prompt is, “What sat on the mat?” The model predicts the next token in the sequence. If it predicts “pizza” instead of “cat,” it knows its guess was wrong.
Here’s where backpropagation comes in. Backpropagation is a process where the model calculates how far off its prediction was (using a measure called the loss function) and works backward to adjust its weights. It updates not just the token embeddings but also the query, key, and value matrices—along with all the other learned parameters—so the next prediction gets closer to the correct answer.
This process—self-attention, feedforward layers, prediction, and backpropagation—repeats over and over again, (billions of times). With each pass, the model becomes more accurate, fine-tuning its ability to predict the correct token and encode increasingly nuanced relationships between tokens.
____________________________________________________________________
So... there is more to this, I am sure. I don’t think it is possible that I asked every question I needed to get a full picture. As stated up top, I will come back and update this post over time as I learn more, but I think this is going to be enough for me to start jumping back into the questions about these models and the potential future of consciousness in AI.
If you made it this far, thank you very much, and hopefully you now understand how these things work better!